
|

|

|
| 32-bit float (no quantization) | 8-bit | 7-bit |

|

|

|
| 6-bit | 5-bit | 4-bit |

|

|

|
| 3-bit | 2-bit | 1-bit |
I recently implemented pastiche—discussed in a prior post—for applying neural style transfer. I encountered a size limit when uploading the library to PyPI, as a package cannot exceed 60MB. The 32-bit floating point weights for the underlying VGG model [1] were contained in an 80MB file. My package was subsequently approved for a size limit increase that could accommodate the VGG weights as-is, but I was still interested in compressing the model.
Various techniques have been proposed for compressing neural networks—including distillation [2] and quantization [3,4]—which have been shown to work well in the context of classification. My problem was in the context of style transfer, so I was not sure how model compression would impact the results.
Experiments
I decided to experiment with weight quantization, using a scheme where I could store the quantized weights on disk, and then uncompress the weights to full 32-bit floats at runtime. This quantization scheme would allow me to continue using my existing code after the model is loaded. I am not targeting environments where memory is a constraint, so I was not particularly interested in approaches that would also reduce the model footprint at runtime. I used kmeans1d—discussed in a prior post—for quantizing each layer’s weights.
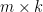 and Q must be
and Q must be 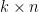 (where D is an
(where D is an 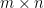 matrix). Additional parameters specify the number of iterations, the learning rate, and the regularization importance.
matrix). Additional parameters specify the number of iterations, the learning rate, and the regularization importance.